

Tuesday, January 29. 2008
Fingerprinting Thaana
What is the frequency of characters in a typical Dhivehi writing? What is the most commonly used Thaana akuru/fili in Dhivehi? Is there a general pattern of akuru and fili to be expected in any given Dhivehi document?
These questions, and especially the latter, kindled my curiosity yesterday and had me off to explore a little bit. Although seemingly trivial and of no practical use, these are serious questions that probe into the finer details of Dhivehi and help produce computational models of Dhivehi - which have practical applications. Even the generalizations and patterns that result from the simplest statistical analysis transcend the (quirks of) individual writing and give a broader picture of what a language is really like. For example, I'm employing a statistical fingerprint of Dhivehi that was generated during this little exercise as part of an experimental procedure that identifies (the presence of Dhivehi) content in web pages. It takes advantage of the fact that the fingerprint for Dhivehi and that for English are dramatically different thus allowing a computer program to discern the type of content it is dealing with - all without really "understanding" a language.
I conducted the analysis on a dataset consisting of ~5000 Dhivehi articles from Haveeru Daily and ~7000 Dhivehi articles from Jazeera Daily. They may not represent the whole varieties of Dhivehi literature available but I think they are a very good approximation - especially of Dhivehi web content which is what I was mostly interested in. My focus was on the individual character level and ran basic mean, mode, variance, standard deviation and frequency calculations with a further character correlation analysis. Despite these being quite simple analyses, I don't think anyone's ever explored as much before and hence the following should make for (exciting!) new information.
Enjoy
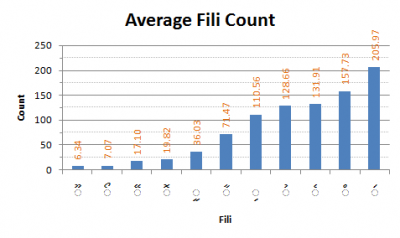
Mean fili usage in Dhivehi writing
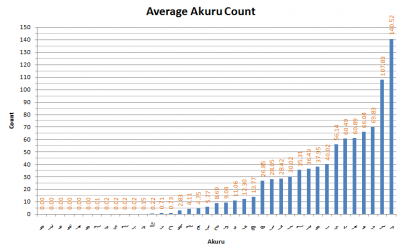
Mean akuru usage in Dhivehi writing
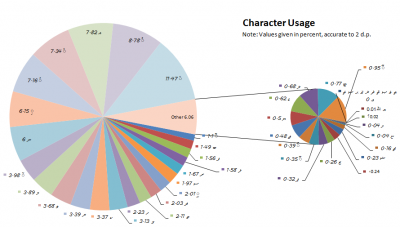
Thaana character frequencies
These questions, and especially the latter, kindled my curiosity yesterday and had me off to explore a little bit. Although seemingly trivial and of no practical use, these are serious questions that probe into the finer details of Dhivehi and help produce computational models of Dhivehi - which have practical applications. Even the generalizations and patterns that result from the simplest statistical analysis transcend the (quirks of) individual writing and give a broader picture of what a language is really like. For example, I'm employing a statistical fingerprint of Dhivehi that was generated during this little exercise as part of an experimental procedure that identifies (the presence of Dhivehi) content in web pages. It takes advantage of the fact that the fingerprint for Dhivehi and that for English are dramatically different thus allowing a computer program to discern the type of content it is dealing with - all without really "understanding" a language.
I conducted the analysis on a dataset consisting of ~5000 Dhivehi articles from Haveeru Daily and ~7000 Dhivehi articles from Jazeera Daily. They may not represent the whole varieties of Dhivehi literature available but I think they are a very good approximation - especially of Dhivehi web content which is what I was mostly interested in. My focus was on the individual character level and ran basic mean, mode, variance, standard deviation and frequency calculations with a further character correlation analysis. Despite these being quite simple analyses, I don't think anyone's ever explored as much before and hence the following should make for (exciting!) new information.
Enjoy
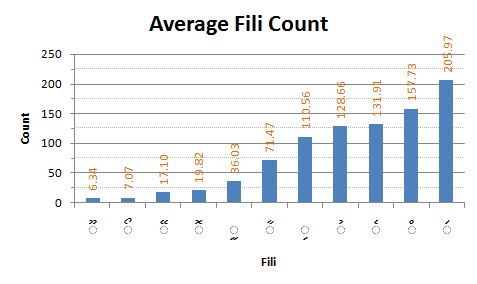
Mean fili usage in Dhivehi writing
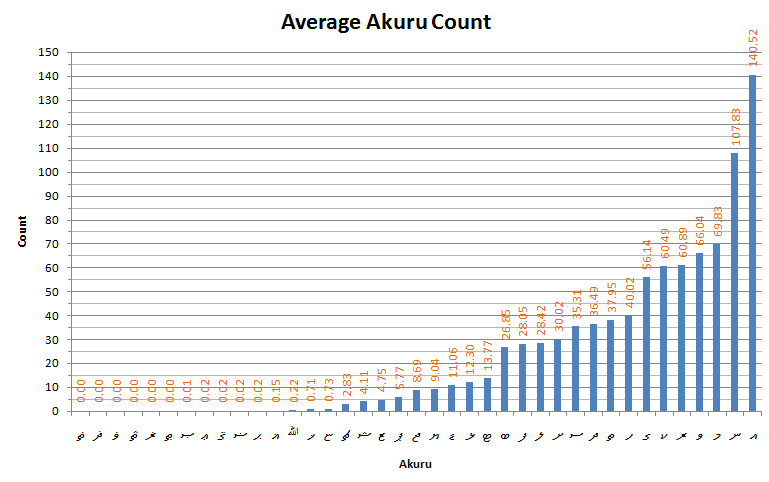
Mean akuru usage in Dhivehi writing
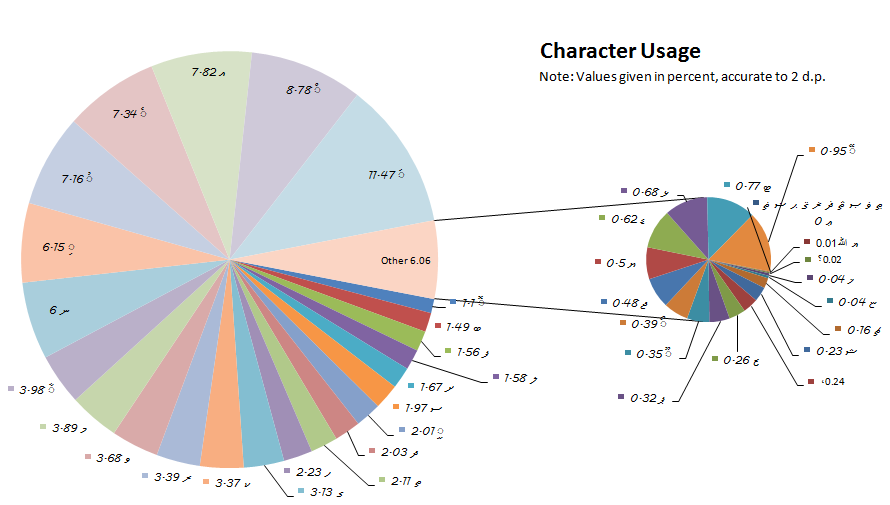
Thaana character frequencies
 ) :- accessing it. It is probably the first time in Maldivian history that a "dhivehi search engine" makes practical sense.
) :- accessing it. It is probably the first time in Maldivian history that a "dhivehi search engine" makes practical sense.

